
防御重放攻击的一些思考与线上实践
重放攻击简单来说就是抓包然后把数据重新再请求一次,相信点进来文章的人都知道是啥就不多啰嗦了。
重放攻击的抵御方法一般都是记录下请求过的数据,在下次请求时拒绝相同的数据。
缓存随机数
{
"params":"data", // 接口参数
"nonce":"abcdefg", // 客户端随机生成的随机数
"sign":"8d777f385d3dfec8815d20f7496026dc", // 签名校验,为了防止请求被篡改做的校验,计算方法:md5(salt + params + nonce + timestamp)
}
在客户端生成随机数,服务端收到请求后到缓存中去查找这个随机数是否被用过了,随机数在缓存中则直接拒绝请求。
为了避免随机数被篡改造成重放攻击,需要添加签名校验,在检查随机数是否在缓存前需要进行校验,防止参数被篡改。
这个方案有两个问题
- 请求量大的时候需要较大的缓存资源
- 并不能完全组织重放攻击,比如说缓存随机数 24 小时,则 24 小时后仍然能再次重放
随机数 + 时间戳校验
绝大部分的博客都讲到使用 随机数 + 时间戳进行重放攻击的拦截,比如说我们需要对一个接口进行重放攻击拦截,接口设计如下:
{
"params":"data", // 接口参数
"nonce":"abcdefg", // 客户端随机生成的随机数
"timestamp":1631345783405, // 客户端的时间戳
"sign":"8d777f385d3dfec8815d20f7496026dc", // 签名校验,为了防止请求被篡改做的校验,计算方法:md5(salt + params + nonce + timestamp)
}
假如说我们只缓存 15 分钟的数据,则服务器所做的工作:
- 判断 timestamp 参数是否与服务器时间差距 15 分钟以上,如果超出 15 分钟则拒绝请求
- 判断签名是否被篡改
- 判断随机数是否在缓存中
在这样的判断下,
15 分钟内生成的随机数会在缓存中被拒绝,
15 分钟后,缓存内随机数过期了,但是请求会在时间戳校验时被拒绝
有挺多的文章到这里就结束了,但是这个方法存在一个很严重的问题,客户端时间可能和服务器时间差距较大,在这样的设备上请求始终会失败,这显然是不可接受的。
为了解决这个问题,可以在客户端中缓存服务器和本地时间的差值,在校验时间失败时,给客户端返回这样的数据:
{
"code": 1001, // 错误码
"timestamp":1631345783405 // 服务器时间戳
}
客户端拿到时间后与本地时间相减,拿到一个时间差,把时间差缓存在本地,后续请求都使用矫正过的时间进行请求。
采用黑名单机制
有时接口需要的响应速度极高,不能接受多余一次缓存查询,而且准确性和及时性要求没有那么高。
比如说账号浏览量统计,可能少量被重放不会出现很大问题,但是不能接受被大量重放。
这时候需要采用黑名单机制,把请求多次的随机数缓存到服务器内存中,再下次请求的时候直接拒绝。
这里给出一个对服务逻辑影响比较小的架构。
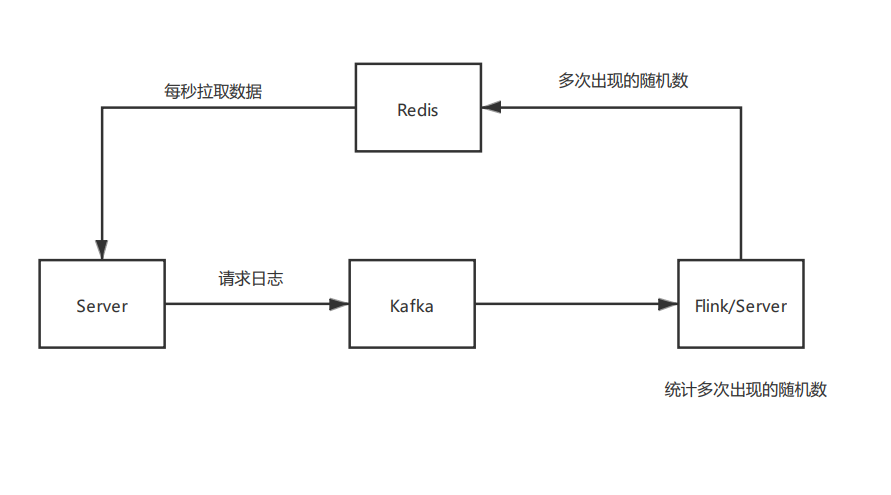
如图,正常来说请求日志都会被消息队列收集起来,从消息队列中接出一份日志到 flink 或者一个单独的统计服务中,计算出现了多次的随机数,再把这批随机数名单定期推送到服务器上即可。可以写到数据库中,然后服务器定期拉取。
服务端拉取到被重放多次的随机数后,把数据加载到内存中,每次请求都去查看一下这个随机数是不是已经在黑名单中了,如果是则直接拒绝。
这个方案的优点在于不会每次请求都去查询缓存,响应速度快。缺点就是只能不是很严谨的拦截重放攻击,在第二次重放请求后才会把随机数加入黑名单。
本文由 鸡米 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Sep 11,2021