
问题发现
最近新上了一个后台服务,在压测的时候发现请求 redis 集群的 CPU 使用率偏高,查询 QPS 是预计的两倍。
测试中使用的是腾讯云的 Redis 官方集群架构。
问题定位
因为只在一处查询了 redis,所以问题还算好定位。
在请求中,会使用 mget 请求同时去请求一个 id 的实时和离线数据。
mget realtime:id offline:id
由于我这边是使用 lettuce 调用的,可以大致点进源码看一下发生了什么。
// io.lettuce.core.cluster.RedisAdvancedClusterAsyncCommandsImpl 285
@Override
public RedisFuture<List<KeyValue<K, V>>> mget(Iterable<K> keys) {
//根据slot来把key分区
Map<Integer, List<K>> partitioned = SlotHash.partition(codec, keys);
// 如果所有的key都在一个slot,则直接mget
if (partitioned.size() < 2) {
return super.mget(keys);
}
// 获得 key-slot关系对
Map<K, Integer> slots = SlotHash.getSlots(partitioned);
Map<Integer, RedisFuture<List<KeyValue<K, V>>>> executions = new HashMap<>();
// 把相同slot的key放到一个mget中去执行
for (Map.Entry<Integer, List<K>> entry : partitioned.entrySet()) {
RedisFuture<List<KeyValue<K, V>>> mget = super.mget(entry.getValue());
executions.put(entry.getKey(), mget);
}
// 等待执行结果完成后对结果进行排序
return new PipelinedRedisFuture<>(executions, objectPipelinedRedisFuture -> {
List<KeyValue<K, V>> result = new ArrayList<>();
for (K opKey : keys) {
int slot = slots.get(opKey);
int position = partitioned.get(slot).indexOf(opKey);
RedisFuture<List<KeyValue<K, V>>> listRedisFuture = executions.get(slot);
result.add(MultiNodeExecution.execute(() -> listRedisFuture.get().get(position)));
}
return result;
});
}
整个方法分为三步:
- 获取分区 slot 和 key 的映射关系,遍历出所需 key 对应的每个分区 slot。
- 遍历 slot 分别请求相应的 redis
- 等待所有请求执行结束,重新组装结果数据
其实看到这里熟悉 redis cluster 的人就已经知道看出来怎么回事了。在这里我的一个 mget 请求被拆为多个 mget 被发送到不同的 redis 分片上了。
RedisCluster 是去中心化的,数据会被分到 16384 个 slot 上,每个 key 会被计算并且存入不同的 slot 中。每个分片负责整个集群的一部分 slot。
当 Redis Cluster 的客户端连接集群时,它也会得到一份集群的 slot 配置信息,这样当客户端要查找某个 key 时,可以直接定位到目标节点。
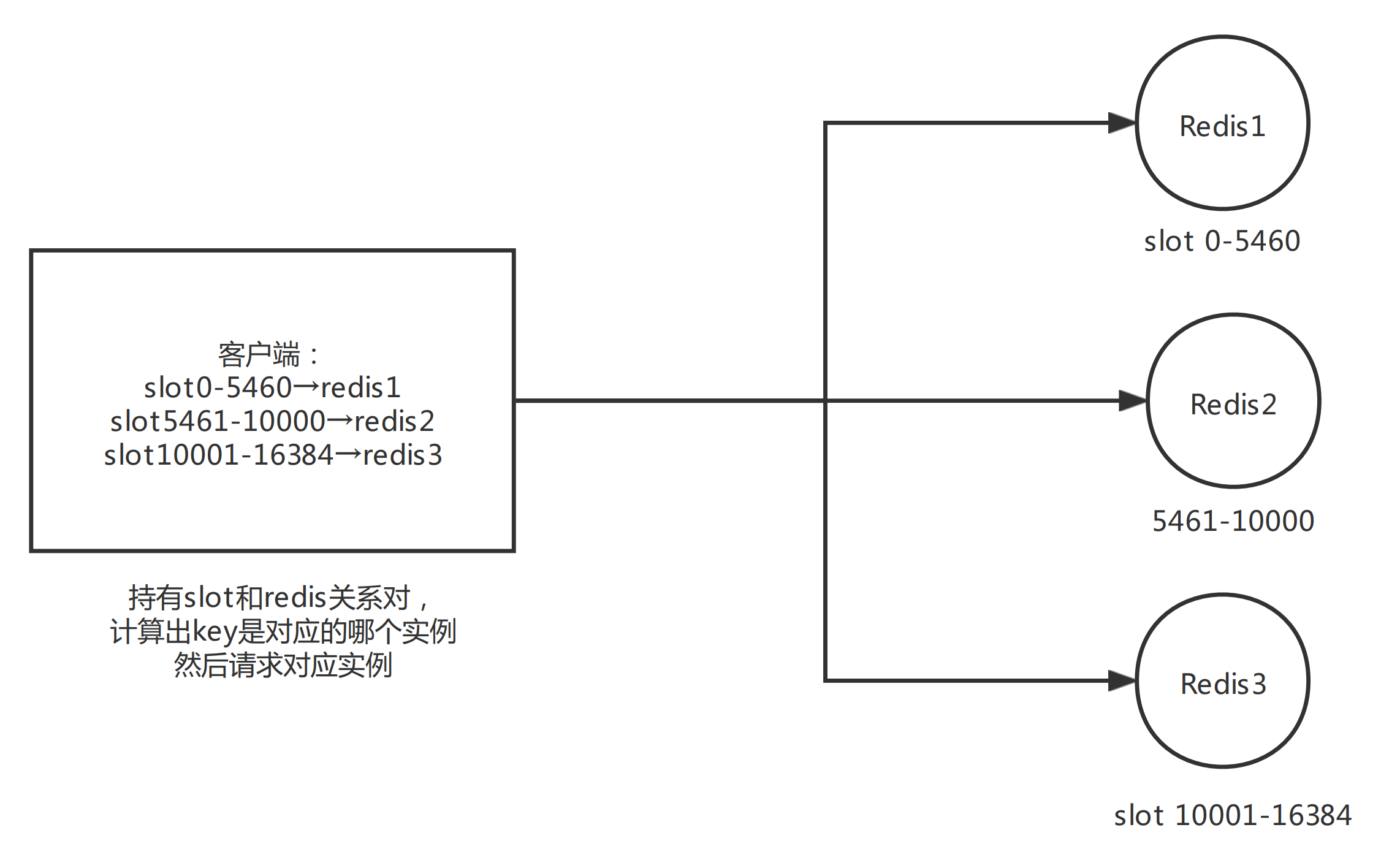
这里由于业务比较特殊,解决方法非常简单,只需要让同一个 id 的实时和离线数据落到同一个 slot 上即可,也就是 mget 的数据是在一个 slot 上。
槽位定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。但是当 key 含有 {} 的时候,redis 会取 {} 内的字符串进行计算槽位。
例如:
database1_key 槽位: crc16(database1_key) % 16384
database1_ 槽位:crc16(key) % 16384 只取{}内的字符串
如果有兴趣,还可以看一下lettuce 定位槽源码:io.lettuce.core.cluster.SlotHash 中 getSlot 方法。
redis 源码中的槽定位算法:
unsigned int keyHashSlot(char *key, int keylen) {
int s, e; /* start-end indexes of { and } */
for (s = 0; s < keylen; s++)
if (key[s] == '{') break;
/* No '{' ? Hash the whole key. This is the base case. */
if (s == keylen) return crc16(key,keylen) & 0x3FFF;
/* '{' found? Check if we have the corresponding '}'. */
for (e = s+1; e < keylen; e++)
if (key[e] == '}') break;
/* No '}' or nothing betweeen {} ? Hash the whole key. */
if (e == keylen || e == s+1) return crc16(key,keylen) & 0x3FFF;
/* If we are here there is both a { and a } on its right. Hash
* what is in the middle between { and }. */
return crc16(key+s+1,e-s-1) & 0x3FFF;
}
通过这个特性,在这个场景下只需要把 key 从原来的
mget realtime:id offline:id
改成
mget realtime:{id} offline:{id}
这样同一个 id 的请求就会落到一个 slot 上,对 redis 的请求数量就减少一半了。
效果
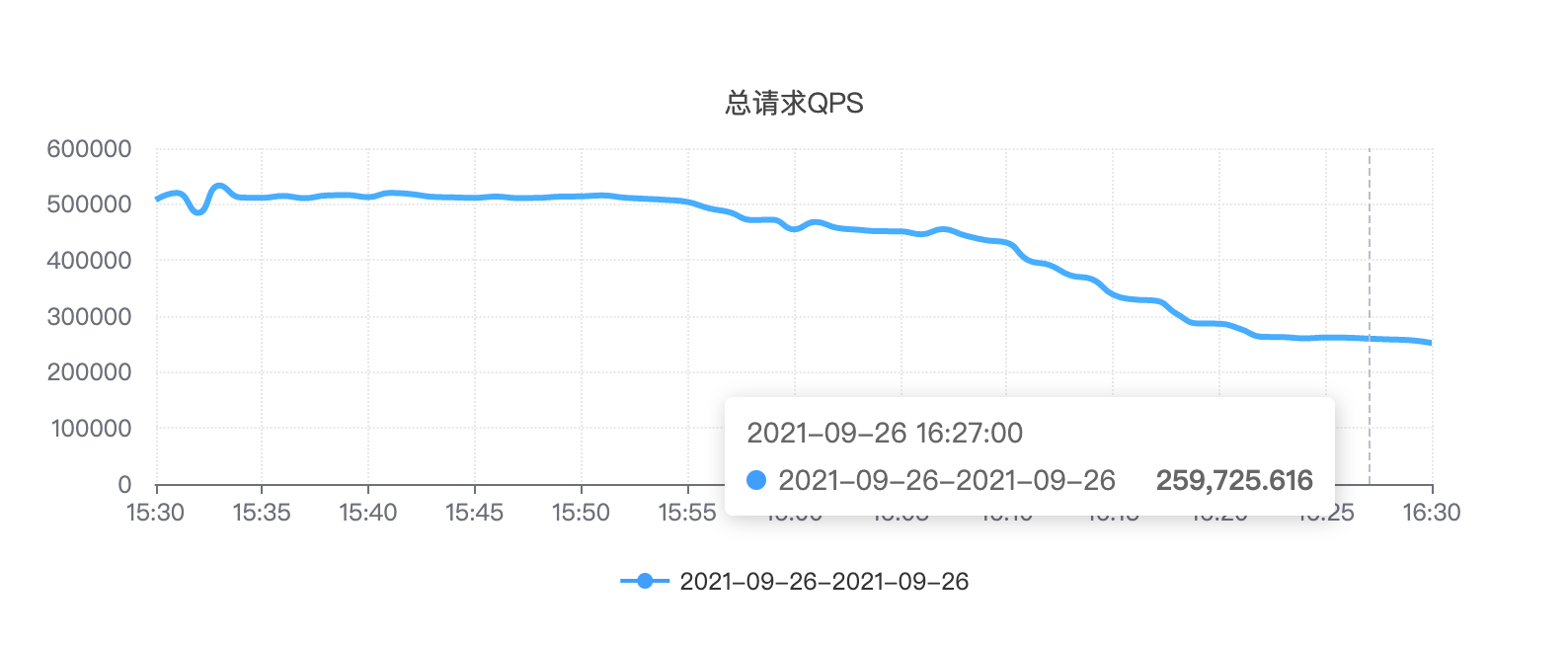
对 redis 请求 QPS 从 原来的 50W 降低到了 26W。
虽然对代码改动的部分非常小,但是效果还是很显著的。
其实不止是 mget,集群下涉及到多 key 操作的命令都可以通过相同的方式进行优化。
参考资料:
《Redis 设计与实现》
Redis 深度历险:核心原理与应用实践
http://ifeve.com/redis-multiget-hole/
本文由 鸡米 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Oct 22,2021